GraphQL is awesome! However, the biggest problem with implementing GraphQL is that you have to do it at origin really. This is due primarily to major caching problems that CDNs cannot solve natively without changing something in their architecture.
For us at The Weather Company, GraphQL solves a particular problem. In order to improve page performance and the performance of data utilization for the web isomorphically, we need to minimize the number of data calls, filter the data payload to retrieve only the data we actually need, and transform the data into a useful format that we want dynamically. This allows us to be data responsible (filtering) to the user and performant (minimizing calls, filtering data, transforming data all dynamically).
As many of us already know, GraphQL provides these quick and easy benefits:
- Single call & response (no binary support)
- Data responsibility
- Reduce, even remove, number of custom endpoints
- Helps avoid duplication of server logic
- Able to deprecate monolith APIs
- A “version-lessor” API
- Empowers applications/clients to fetch data more efficiently
- Give client data to know what data is being used
- Enables client to apply cognitive computing to the API
However, I do not want to spend time talking about the problem GraphQL solves or even its benefits. Instead I want to talk about the edge caching problems. GraphQL can easily be used irresponsibly causing major caching problems. It's not that GraphQL cannot be cached. Instead, it is that misuse of GraphQL can lead to a poor utilization of cache massively reducing your cache-hit ratio. So what are these problems??
Caching Problems with GraphQL
There are three major problems with caching GraphQL:
- Duplicate Cache
- Overlapping Cache
- Cache Times
Before I continue, consider this POST request (at /q?query=) as our base request that we are going to compare.POST /gql
| query{ | |
| observations(geocode: "38.00,-97.00", unit: METRIC, locale: "en-US") { | |
| temperature, | |
| feelsLike, | |
| snowDepth | |
| }, | |
| astro(locId:"38.00,-97.00", language:"en-US", min:0, max:3) { | |
| dateLocal, | |
| sun { | |
| riseSet { | |
| riseLocal, | |
| setLocal | |
| } | |
| } | |
| } | |
| } |
In the base request, we are making a single GraphQL request to aggregate two atomic APIs (observations and astro) taking only a subset of properties provided in the response. I will use this example as my reference point for each of the following examples to highlight the problems.
Duplicate Cache
Duplicate cache is simply when there is a duplicate value for more than one key. Simply, this is when there are more than one URLs result in the same response or cache value. For example, if https://api.example.com/cache-key-1 and https://api.example.com/cache-key-2 both resulted in the same response {"something":"goes here"}. Poor, undisciplined use of GraphQL causes this.
1. Duplicate Cache from “Whitespace”
POST /gql
| query{observations(geocode: "38.00,-97.00", unit: METRIC, locale: "en-US") { | |
| temperature, | |
| feelsLike | |
| }, | |
| astro(locId:"38.00,-97.00", language:"en-US", min:0, max:3) { | |
| dateLocal, | |
| sun { | |
| riseSet { | |
| riseLocal, | |
| setLocal | |
| } | |
| } | |
| } | |
| } |
The only thing different in this request is the removal of "whitespace" before observations (nt). This is a complete duplicate cache of the original, base request.
2. Duplicate Cache from Property Ordering
POST /gql
| query{ | |
| observations(geocode: "38.00,-97.00", unit: METRIC, locale: "en-US") { | |
| feelsLike, | |
| temperature, | |
| snowDepth | |
| }, | |
| astro(locId:"38.00,-97.00", language:"en-US", min:0, max:3) { | |
| dateLocal, | |
| sun { | |
| riseSet { | |
| riseLocal, | |
| setLocal | |
| } | |
| } | |
| } | |
| } |
The only thing different in this request is the re-ordering of observations's properties. Originally it was temperature, feelsLike, and then snowDepth. Here feelsLike appears first. This again is a complete dupplicate cache of the original, base request.
3. Duplicate Cache from Method Type
GET /gql?query=
| { | |
| observations(geocode: "38.00,-97.00", unit: METRIC, locale: "en-US") { | |
| temperature, | |
| feelsLike, | |
| snowDepth | |
| }, | |
| astro(locId:"38.00,-97.00", language:"en-US", min:0, max:3) { | |
| dateLocal, | |
| sun { | |
| riseSet { | |
| riseLocal, | |
| setLocal | |
| } | |
| } | |
| } | |
| } |
The only thing different in this request is the method type (GET v. POST). The graphs and responses are completely the same.
4. Duplicate Cache from Variables
POST /gql
| query(location:String!){ | |
| observations(geocode:$location, unit: METRIC, locale: "en-US") { | |
| temperature, | |
| feelsLike, | |
| snowDepth | |
| } | |
| astro(locId:$location, language:"en-US", min:0, max:3) { | |
| dateLocal, | |
| } | |
| } | |
| variables{"locations":"38.00,-97.00"} |
Here is a very different graph than the base graph. Using graphs like this this graph is completely re-usable and provides a standard to prevent cache duplication due to variations previously discussed (e.g., whitespace and ordering). However, in the cache, this still duplicates the cache from the previous three examples.
Overlapping Cache
Besides cache duplication, there is cache overlapping. Cache overlapping occurs when portions of the response/cache are exactly the same with very minimal differences. Now, this is an obvious result of aggregation. Instead of caching the APIs atomically, the GraphQL API call is being cached. As a result, GraphQL calls will take longer than calling each API independently and asynchronously.
1. Overlapping Cache from Different Properties
POST /gql
| query{ | |
| observations(geocode: "38.00,-97.00", unit: METRIC, locale: "en-US") { | |
| temperature, | |
| feelsLike | |
| }, | |
| astro(locId:"38.00,-97.00", language:"en-US", min:0, max:3) { | |
| dateLocal, | |
| sun { | |
| riseSet { | |
| riseLocal, | |
| setLocal | |
| } | |
| } | |
| } | |
| } |
The only thing different in this request is the removal of snowDepth from the observations graph. While the singular response is different from the previous, the cache has massive overlap (duplicate of astro, etc.). Essentially this response is entirely contained in the base, original response.
Or even consider the addition of a property.
| query{ | |
| observations(geocode: "38.00,-97.00", unit: METRIC, locale: "en-US") { | |
| temperature, | |
| feelsLike, | |
| snowDepth, | |
| heatIndex | |
| }, | |
| astro(locId:"38.00,-97.00", language:"en-US", min:0, max:3) { | |
| dateLocal, | |
| sun { | |
| riseSet { | |
| riseLocal, | |
| setLocal | |
| } | |
| } | |
| } | |
| } |
The only thing different in this request is the addition of
heatIndex to the observations graph. While the singular response is different from the previous, the cache has massive overlap (duplicate of astro, full embodiment of the original, base observations graphs).
2. Overlapping Cache from Property Renaming
POST /gql
| query{ | |
| observations(geocode: "38.00,-97.00", unit: METRIC, locale: "en-US") { | |
| temperature, | |
| MyTemp: feelsLike, | |
| snowDepth | |
| }, | |
| astro(locId:"38.00,-97.00", language:"en-US", min:0, max:3) { | |
| dateLocal, | |
| sun { | |
| riseSet { | |
| riseLocal, | |
| setLocal | |
| } | |
| } | |
| } | |
| } |
The only thing different in this request is the renaming of feelsLike to MyTemp. While the singular response is different from the previous, the cache has massive overlap (duplicate of astro, etc.). Essentially the base, original response contains all the data this response needs.
Cache TTLs
Finally, cache expires time (or TTL) becomes problematic. Take three weather.com APIs: observations, alerts, and daily-forecast. observations has a 15 minute cache, daily-forecast has an hour cache, but alerts has a 1 minute cache. If I were to do a graph with alerts, now my GraphQL call cache TTL is 1 minute. This will result in 15x more origin calls to observations and 60x more origin calls to daily-forecast; otherwise, my alerts portion of the response grows stale. Both of these affects hurt my cache-hit ratio immediately.
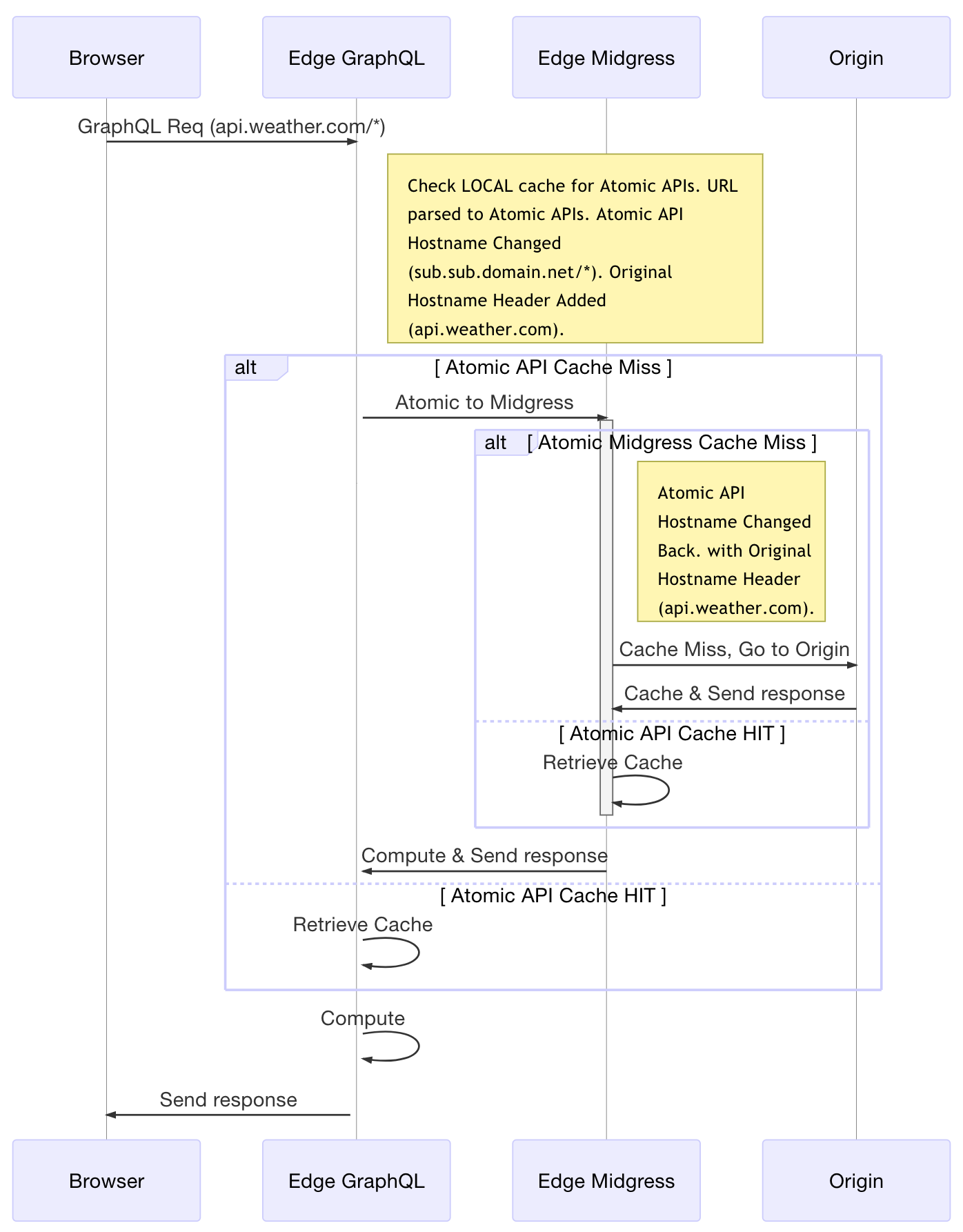
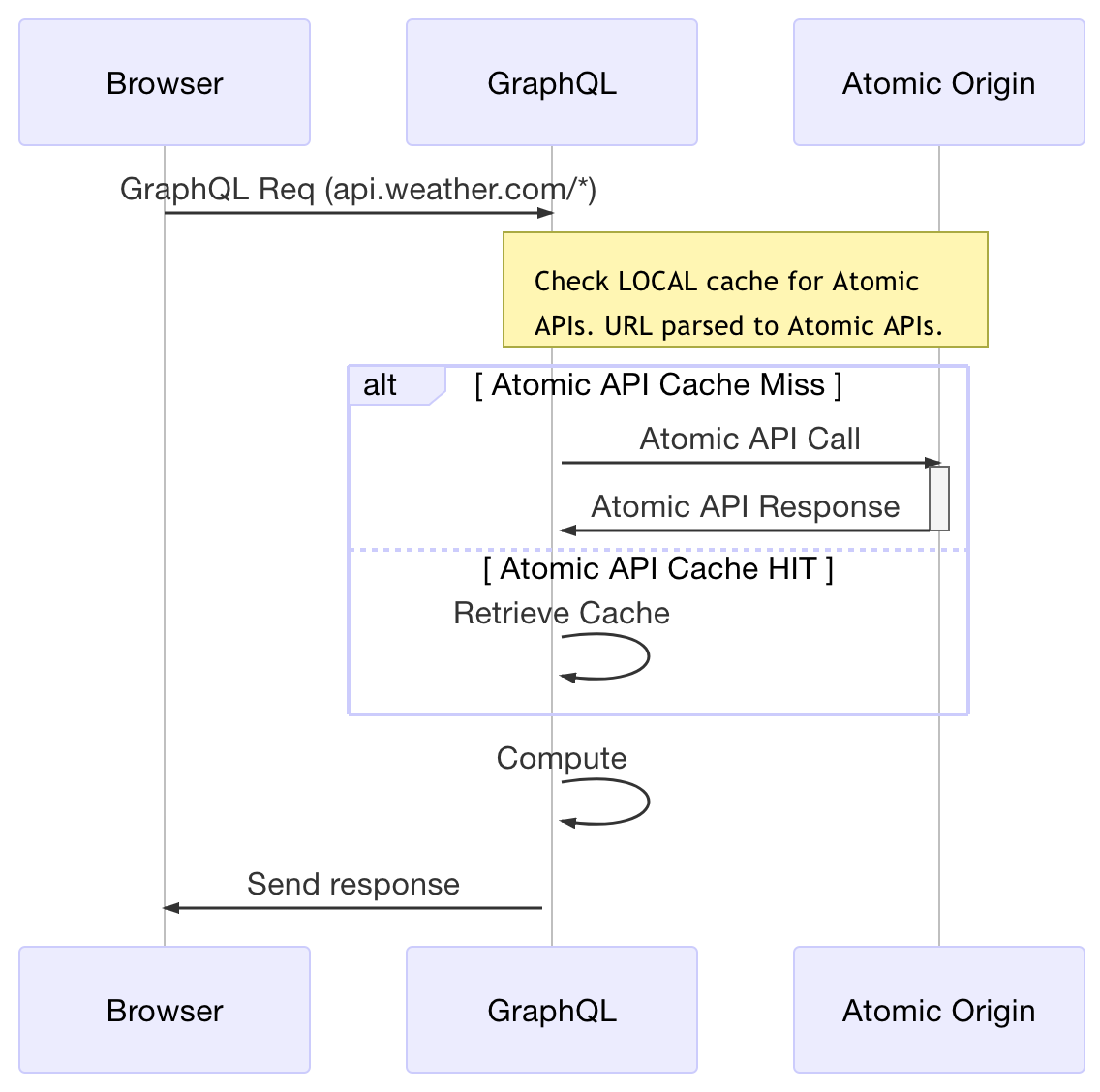
Solution: Compute at the Edge
To me, the only way to solve this problem is at the edge, or at a CDN. The CDNs must then be able to cache each API in the graph atomically and be able to sanitize and normalize the cache key (always containing the request URL/path [+ body for non-GET]). In a GraphQL call, this means that the cache key must normalize whitespace and ordering (recursively). Because of the limitations of the URI in browsers, GraphQL POSTs are often used. Terminating SSL and unwrapping the body to decompose or normalize it becomes a performance and security issue. So, to get out of all those things the best option IMHO is to cache the atomic APIs only. This preserves the best of the cache that can be shared across the atomic API calls and the shared, aggregate GraphQL calls.
CDNs are becoming a commodity, and I truly believe the first one to enable compute that the edge will win the CDN war, or minimally have a huge advantage over the competition. Here are a couple request solutions/examples that could easily prove out to be what could happen. I have spoken to more than thirty (30) CDNs and to several of the major CDNs about this in detail, including Akamai, Fastly, Limelight, Highwinds, Cloudflare, CDNetworks, and AWS Cloudfront. While I cannot divulge too much here, I can emphatically state that the leaders in this area will be Cloudflare and Fastly. While AWS Cloudfront was first to the market, their Lambda at the Edge is quite limited and restrictive, almost not useful. Cloudflare is already the leader in this area with their edge workers (product detail). Tyler McMullen, from Fastly, has an impressive solution in the works that I believe will ensure solid performance, scale, security and isolation. Akamai's new product incubation team has created something solid, especially for enterprises. For both Fastly and Akamai, I am not sure when these will be released into the wild though I would place a bet on Fastly launching first.
2022 Update: Akamai, Fastly, Cloudflare all have edge solutions where you can run or configure GraphQL specific caching. With AWS Cloudfront + Lambda@Edge, you can build out your own GraphQL implementation following a variety of tutorials like this one.
GraphQL at the Edge
GraphQL on the Edge Compute with Midgress Cache